Abstract
Data mining is an interdisciplinary field (databases, machine learning and statistics) that focuses, according to definition, on nontrivial extraction of implicit, previously unknown, and potentially useful information from data. The goal of the research is to find out and describe possible domains for data mining in military environment. There are many well known data mining implementations in areas like telecommunication, biology, market analysis, etc, but these are not too related to our area of interest. Military environments with modern C4ISR systems produce large amount of well described etc. For each domain that will be defined, we would like to describe existing data sources, the quality of sources and usability of such sources, methods that can be applied (like decision trees, neural networks, etc.) to get applicable result, domain users that can use provided results. We already started data sources analysis research, created two data warehouse prototypes in financial and personnel areas.
The aim of the paper is to describe current research results, describe possible domains which were already identified and publish experience we got during experimentations.
Data mining definition
Data mining (DM), also called Knowledge-Discovery in Databases (KDD) is the process of automatically searching large volumes of data for patterns such as association rules. It is a fairly recent topic in computer science but applies many older computational techniques from statistics, information retrieval, machine learning and pattern recognition.
Types of problems and related methods
Usually, the data mining project involves a combination of different problem types, which together solve the business problem [CRISP]. Methods are enclosed in brackets.
- Data Description and Summarization aims at the concise description of characteristics of the data, typically in elementary and aggregated form. This gives the user an overview of the structure of the data. Sometimes, data description and summarization alone can be an objective of a data mining project. All experiments we have held started with this phase.
- The data mining problem type segmentation aims at the separation of the data into interesting and meaningful subgroups or classes. All members of a subgroup share common characteristics (clustering techniques, visualization, neural nets).
- Concept description aims at an understandable description of concepts or classes. The purpose is not to develop complete models with high prediction accuracy, but to gain insights (rule induction methods, conceptual clustering).
- Classification assumes that there is a set of objects - characterized by some attributes or features - which belong to different classes. The class label is a discrete (symbolic) value and is known for each object. The objective is to build classification models (sometimes called classifiers), which assign the correct class label to previously unseen and unlabeled objects. Classification models are mostly used for predictive modeling. (discriminant analysis, rule induction methods, decision tree learning, neural nets, K-nearest neighbor, case-based reasoning, genetic algorithms)
- Another important problem type that occurs in a wide range of applications is prediction. Prediction is very similar to classification. The only difference is that in prediction the target attribute (class) is not a qualitative discrete attribute but a continuous one. The aim of prediction is to find the numerical value of the target attribute for unseen objects. (regression analysis, regression trees, neural nets, K-nearest neighbor, box-jenkins methods, genetic algorithms).
Types of data
According to [RUD01] there are three types of data, no matter where it comes from. Data falls into three basic types: demographic, behavioural, and psychographic or attitudinal.
- Demographic data generally describes personal or household characteristics. It includes characteristics such as gender, age, marital status, income, home ownership, dwelling type, education level, ethnicity, and presence of children.
- Behavioural data is a measurement of an action or behaviour. Depending on the industry, this type of data may include elements like sales amounts, types and dates of purchase, payment dates and amounts, customer service activities, insurance claims or bankruptcy behaviour, and more. Web site activity is another type of behavioural data.
- Psychographic or attitudinal data is characterized by opinions, lifestyle characteristics, or personal values. Traditionally associated with market research, this type of data is mainly collected through surveys, opinion polls, and focus groups.
During our experimentation mostly data from the first and second groups were used. As far as we know there are not many opinion pools held in military environment.
Standardization
There are many areas of standardization. It is necessary to follow these standards for interoperability capability. The following are the main standardization efforts:
- Predictive Model Markup Language (PMML) developed by the Data Mining Group (www.dmg.org). It is interchange format for data mining models based on XML.
- Java Data Mining API specification request (JSR-000073). Support for data mining APIs on J2EE platforms. The aim is to build, manage, and score models programmatically. The API request is supported by Oracle, Sun, IBM, etc
- OLE DB for Data Mining by Microsoft. Its table based specification that incorporates PMML.
Data sources
During research the following types of data sources were identified:
- Information systems with databases (e.g. operational systems for logistics, personnel, financial, command support). This is primary area of interests. We already described and identified the key information systems that can be sources for data mining.
- Sensors (e.g. detectors, radiolocation). These data sources are usually continuous.
- Communication infrastructure (e.g. log files of equipments).
- Publicly available sources (e.g. internet groups, web pages of companies).
Domains - vertical and horizontal
These domains can be identified by two basic approaches:
- By organization structure (vertically). The first level of such structure is based on force types (land forces, air forces, maritime forces, special forces, military police). The next level is dependent on each mentioned type.
- By groups of interests. These groups can communicate between organization structure elements (horizontally). Groups usually share data and information or at least share type of data and information. E.g. logistics, personnel, financial areas.
Experiment
In the following part of a paper a simple example of data mining techniques is described. Personnel domain was selected for this example. This experiment was focused on everyday requirements of battalion commander. The question was whether data mining can support everyday decisions of commander. The bottom up approach was taken during this experiment. We focused on data that are available to the commander like financial, personnel and logistics data, but data only produced or used at the battalion level.
Using bottom/up approach, we analyzed data that are inserted to applications through input forms and provided by output reports. The data structures of underline applications were unknown to us. On the Figure 1
there is an example of such input form. We analyzed 25 different forms/reports in this experiment.
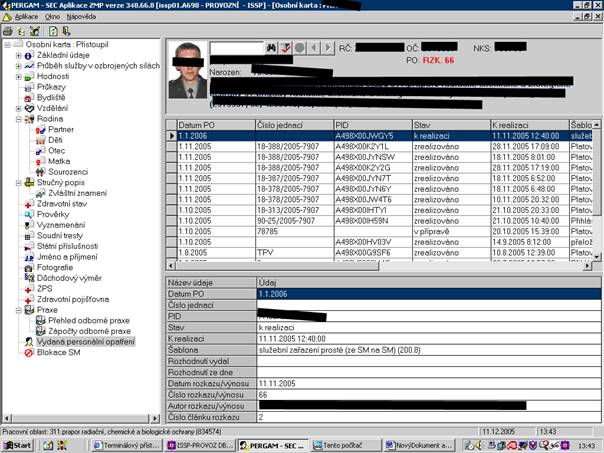
Figure 1: Data form example
For each form or related forms data entity was built and described (see examples of data description on images Figure 2, Figure 3
).
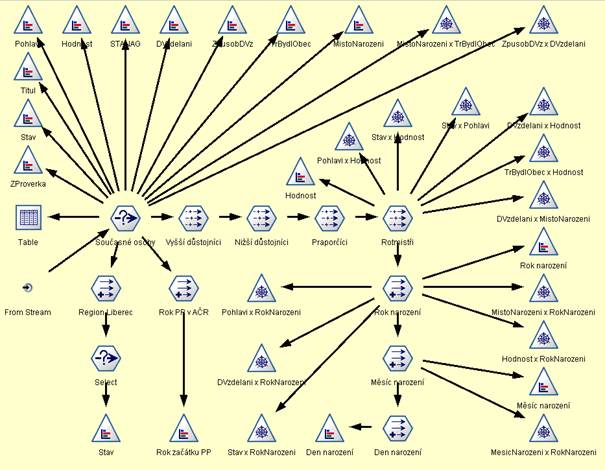
Figure 2: Data description (complex one - personnel characteristics)
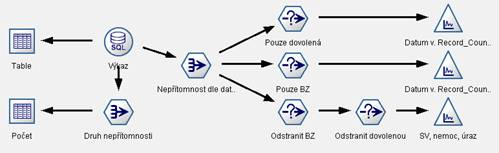
Figure 3: Data description (simple one - absense analysis)
On the next picture (Figure 4
) we can find an example of data understanding output. Usually column graphs, histograms, tables, plots or web graph were used for visualization.
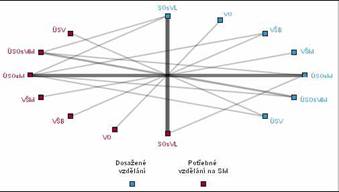
Figure 4: Data understanding example (Web graph - achieved x required education)
Previous data desription and undestanding phases are only preparation phases for a data analysis. At this stage, after data are comprehensible for analyst, more sophisticated analysis can be held on existing data. This include data segmentation, classification, dependency analysis, etc. As a small example of such analysis, let me explain a possible question that can commander ask.
Is there any dependence between personnel absence and regular outdor exercises? Results were as follows (Figure 5 ).
- Absence (sikness) before exercise has increased. Further analysis was carried out and according to this analysis three persons were identified, which are visiting a doctor regularly before each exercise. Commander can focus more on these "cheaters" and take some precaution.
- Absence (sikness) after exercise has increased as well. This is a result of low stamina and resistence of a group of persons. Again, the group can be identified.
Conclusion
The aim of the paper was describe expected results of data mining usage in military environment. Domains of interests for data mining are identified; typical tasks are assigned to each domain. We are at the stage data sources identification and classification. We already tackled several real examples in personnel and financial areas (as described above) and data continuously produced by sensors.
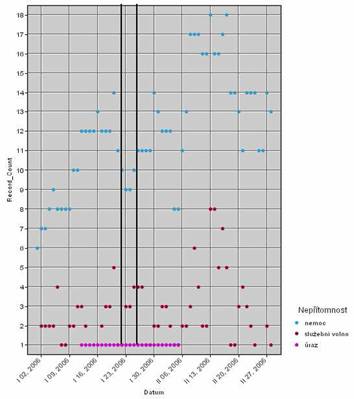
Figure 5: Analysis output - indisposed persons during a time period (two months)
References
[RUD01] |
Olivia Parr Rud, Data Mining Cookbook, Modeling Data for Marketing, Risk, and Customer Relationship Management, John Wiley & Sons, Inc., 2001, ISBN 0-471-38564-6 |
[HMS01] |
Hand, D., Mannila, H., Smyth, P. : Principles of Data Mining. MIT Press, Cambridge, MA, 2001. ISBN 0-262-08290-X |
[TAI03] |
Taipale, K.A., Data Mining and Domestic Security: Connecting the Dots to Make Sense of Data, Center for Advanced Studies in Science and Technology Policy. 5 Colum. Sci. & Tech. L. Rev. 2 , Dember 2003. |
[CRISP] |
CRISP/DM 1.0 manual. Step-by-step data mining guide. |
 Back Back
 Back to TOC Back to TOC
|
